Repenser l’annotation des domaines fonctionnels de protéines pour des données plus fiables.
Misannotated domains in plant databases: lessons from ‘PIPLC Y-box-containing’ proteins
Lucas Amokrane, Sébastien Aubourg, Eric Ruelland.
Trends in Plant Science, In press, ⟨10.1016/j.tplants.2026.04.005⟩.
Dans leur dernier article paru dans Trends in Plant Science, Lucas Amokrane (doctorant), Eric Ruelland (chercheur CNRS) accompagné de Sébastien Aubourg de l’INRAE Angers s’interrogent sur la propagation d’erreurs dans les bases de données de protéines basées sur les domaines fonctionnels.
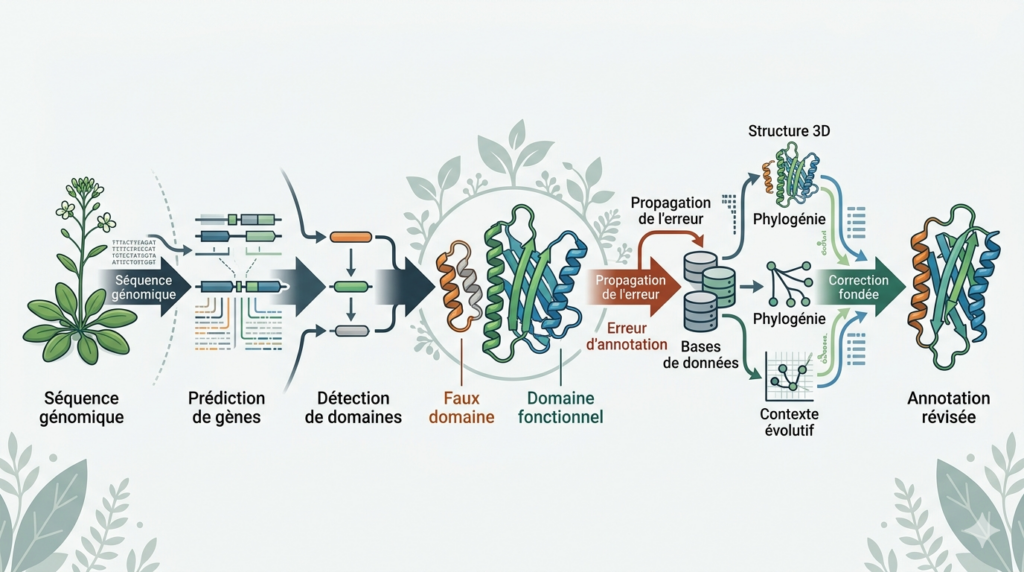
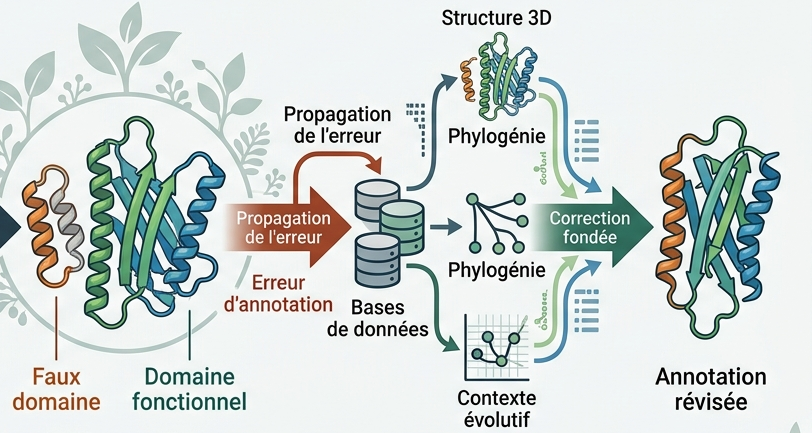
En se basant sur l’exemple de leur modèle d’étude et en utilisant le terme « phosphoinositide-dependent phospholipase C Y-box-containing », ils ont pu démontrer les dérives associées à l’annotation automatique qui diffuse dans les bases.
Il apparait que la prise en compte de données structurales devient indispensable en complément de celles des séquences pour s’assurer d’une annotation fiable.